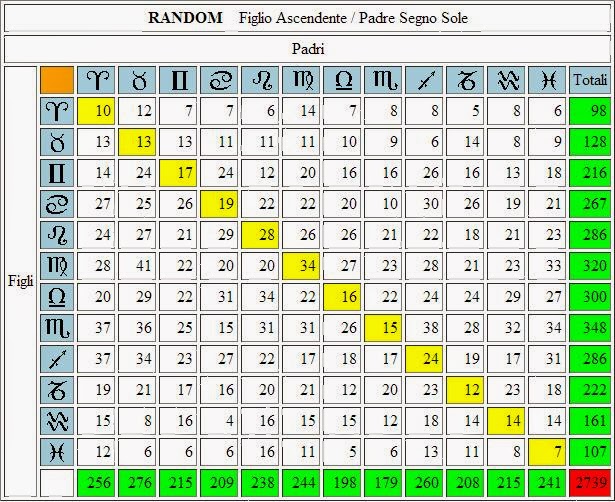
Falsa significatività (Expected = 198)
Tabella Reale:
10 + 20 + 17 + 29 + 17 + 31 + 25 + 18 + 25 + 18 + 15 + 9 = 234
Tabelle Random:
7 + 13 + 15 + 17 + 28 + 30 + 18 +16 + 27 + 11 +18 + 8 = 208
8 + 8 + 12 + 22 + 24 + 36 + 15 + 26 + 28 + 18 + 11 + 6 = 214
10 + 13 + 17 + 19 + 28 + 34 + 16 + 15 + 24 + 12 + 14 + 7 = 209
9 + 17 + 13 + 16 + 25 + 26 + 16 + 20 + 20 + 17 + 11 + 8 = 198
Se ogni volta che si mischiano le famiglie si ottiene un numero diverso è EVIDENTE che non si può utilizzare questo numero per confrontarlo con il numero trovato nella tabella con i dati reali.
E' come pretendere di prendere le misure di un mobile con un metro che a volte è lungo 120 cm, altre volte 80 cm, altre volte 90 cm ecc. ecc.
Il numero delle coppie sulla diagonale centrale della tabella con i dati reali rimane sempre lo stesso, queste coppie sono 234, ma con quale di questi 4 numeri trovati nelle tabelle random andrebbe confrontato?
Se si confronta 234 con 198, allora il risultato trovato appare essere molto significativo, ma se si confronta con gli altri tre numeri no.
Se invece calcoliamo la media tra i quattro risultati ottenuti mischiando le famiglie, otteniamo un valore più vicino al vero valore atteso.
Media = (208 + 214 + 209 + 198) / 4 = 207
In realtà anche questo valore è piuttosto lontano dal valore atteso che è 223, ma questo succede perché abbiamo usato solo quattro tabelle random, mentre ne occorrerebbero un centinaio, e perché siamo stati "sfortunati" perché il valore trovato per la quarta tabella è molto raro.
Quello che è importante sottolineare è l'assurdità del metodo di Discepolo che consisteva nel prendere come valore atteso il primo valore che otteneva mischiando le famiglie una unica volta.
Nessun professore universitario di statistica certificherebbe la validità del metodo di Discepolo, ed infatti i professori universitari non hanno mai detto che questo metodo era valido.
Io credo che i professori universitari abbiano dato per scontato che Discepolo avesse calcolato la media su un centinaio di randomizzazioni diverse, ed è per questo che hanno calcolato i valori di significatività basandosi sui numeri che gli erano stati forniti da Discepolo, altrimenti non l'avrebbero fatto.
Quando l'equivoco è stato chiarito, i professori universitari hanno detto a Discepolo che doveva calcolare la media su 100 randomizzazioni per trovare il valore atteso, ma Discepolo ha pensato di ignorare i loro consigli e di continuare con il metodo utilizzato all'inizio.
In alto vedete una immagine che indica la significatività statistica se si utilizza come valore atteso il valore più basso tra le quattro randomizzazioni. In realtà il valore del P-Value non è esatto perché le formule che ho utilizzato non sono adatte a questo tipo di problema.
Qualche tempo fa, dicevo che il P-Value calcolato con queste formule fosse esatto, in realtà non è proprio così. Queste formule permettono di trovare con una buona approssimazione il P-Value, ma non di calcolarlo esattamente. La cosa non è importante da un punto di vista pratico, perché anche se il P-Value è leggermente diverso da quello calcolato, il risultato non cambia.
Ad esempio nel grafico si legge che il P-Value è 0,00881 ma anche se fosse invece uguale a 0,009 o a 0,007 da un punto di vista pratico non cambierebbe nulla. Il P-Value ci dice qual è la probabilità di trovare un certo risultato per caso, e se questa probabilità è di sette casi su mille, di otto casi su mille, o di nove casi su mille, non cambia praticamente nulla, perché in tutti e tre i casi si tratta di una probabilità molto scarsa.
Credo che l'unico modo per calcolare in modo esatto il valore del P-Value in questo tipo di problema, sia proprio quello di calcolarlo per mezzo di simulazioni che facciano ricorso a dei numeri random, e sto lavorando su questo.
Non ci provo nemmeno a spiegarvi perché il calcolo del P-Value effettuato con le mie formule sebbene fornisca una buona approssimazione non sia da considerarsi esatto, perché ho visto che non mi seguite nelle cose più semplici, e questo tanto semplice da capire non è.
Quello che invece dovrebbero capire TUTTI, è che il metodo di Discepolo di prendere come valore atteso il primo valore che si ottiene mischiando le famiglie, è un metodo assurdo, perché mischiando le famiglie si ottengono ogni volta dei risultati diversi.
Questa cosa in realtà l'ha capita lo stesso Discepolo, molto prima che fossi io a spiegargliela.
E' allo stesso Discepolo che a un certo punto è venuto in mente di controllare che cosa succedeva se invece di mischiare le famiglie una unica volta le mischiava per 100 volte.
E' lo stesso Discepolo che ha constatato che ripetendo queste randomizzazioni per 100 volte otteneva quasi sempre dei risultati diversi, per cui lui stesso si sarebbe dovuto rendere conto che il metodo utilizzato all'inizio non era valido.
Perché allora non ha corretto il suo errore?

Non significativo (expected= 223)