Clicca sull'immagine per leggere il testo
Il testo riportato nell'immagine qui sopra è tratto dal libro di Ciro Discepolo: "Osservazioni politematiche sulle ricerche Discepolo/Miele".
Discepolo a questo punto delle sue ricerche si è reso (finalmente) conto, che utilizzando i numeri random o meglio i numeri pseudo random generati dal computer, ottiene dei risultati che variano di volta, in volta, e quindi si domanda esisterà un metodo oggettivo per scegliere quale tra questi risultati è quello giusto?
Bisognerà tener conto dei transiti del ricercatore?
Ci rendiamo conto allora, che stiamo trattando una materia di confine tra la scienza e verità esoteriche non ancora chiaramente decifrabili. E forse questa potrebbe essere una spiegazione del fatto che occorrerebbe individuare un metodo "oggettivo" per portare avanti valori di ricerca statistica, assicurandosi che i transiti del ricercatore, in quel momento, non saranno determinanti, alla fine, per il risultato della ricerca.

Pazzesco!
Il metodo "oggettivo" cercato da Discepolo c'è, anzi di metodi ce ne sono almeno due.
Uno di questi metodi si basa proprio sull'utilizzo dei numeri casuali. Quello che probabilmente Discepolo non ha capito, è che una procedura basata sui numeri casuali può portare ad un risultato certo e per nulla casuale.
Il trucco qual è?
Invece di prendere un singolo risultato casuale ottenuto mischiando le famiglie, i risultati vanno presi TUTTI.
Quello che interessa sapere, non è quello che avviene in una singola randomizzazione, ma quello che succede in una serie di randomizzazioni, in modo da poter disegnare una curva che indica la frequenza con cui si ripetono i risultati e quindi la loro probabilità.
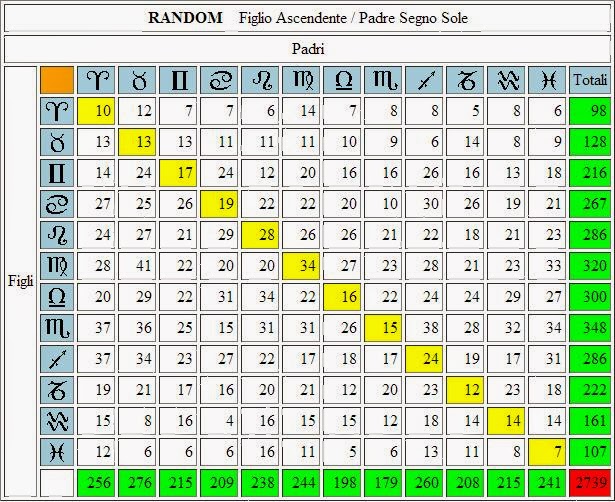
Se ad esempio prendiamo 100 risultati casuali ottenuti mischiando le famiglie del file paris12, e costruiamo un grafico con questi risultati, otteniamo la curva a campana che si vede sulla copertina del libro di Discepolo.

Sull'asse delle x ci sono i risultati ottenuti, mentre quello delle y indica la frequenza con cui questi risultati si ripetono.Questa curva ci dice che ci sono dei risultati che sono più frequenti e altri che sono meno frequenti.
I risultati più frequenti si trovano sull'asse delle x in corrispondenza del dosso della curva al centro dell'immagine, mentre a mano a mano che ci si allontana dal centro in una direzione o nell'altra, i risultati sono via, via, meno frequenti.
Una volta disegnata questa curva possiamo vedere il risultato ottenuto con le coppie vere in che punto del grafico si colloca. Se il risultato ottenuto con le coppie vere si trova nella zona centrale del grafico non è significativo, se invece si trova in una delle due estremità di questa curva è statisticamente significativo.
Se invece si mischiano le famiglie una sola volta, come aveva fatto inizialmente Discepolo, non è possibile disegnare la curva che si vede nel grafico, perché per disegnare questa curva, abbiamo bisogno di una serie di risultati casuali.
Forse a qualcuno la cosa potrebbe sembrare strana, ma se si procede in questo modo, utilizzando delle procedure che utilizzano i numeri random del computer, il risultato finale non è affatto random.
Perché se ad esempio ripetiamo questa procedura basata su una serie di 100 randomizzazioni per 10 volte, il risultato indicato come più probabile sarà lo stesso in ciascuna di queste 10 simulazioni.
Se questo non dovesse accadere, allora abbiamo bisogno di aumentare il numero delle randomizzazioni, e invece di effettuarne 100 ne effettueremo 1000.
Con un congruo numero di randomizzazioni, che non occorre definire in anticipo ma che si può stabilire sulla base dei risultati ottenuti, il risultato finale è sempre lo stesso.
Per cui questo è il metodo oggettivo auspicato da Discepolo, e che non risente affatto dei transiti che sta avendo il ricercatore in quel momento.